
Advanced Analytics Target Architecture
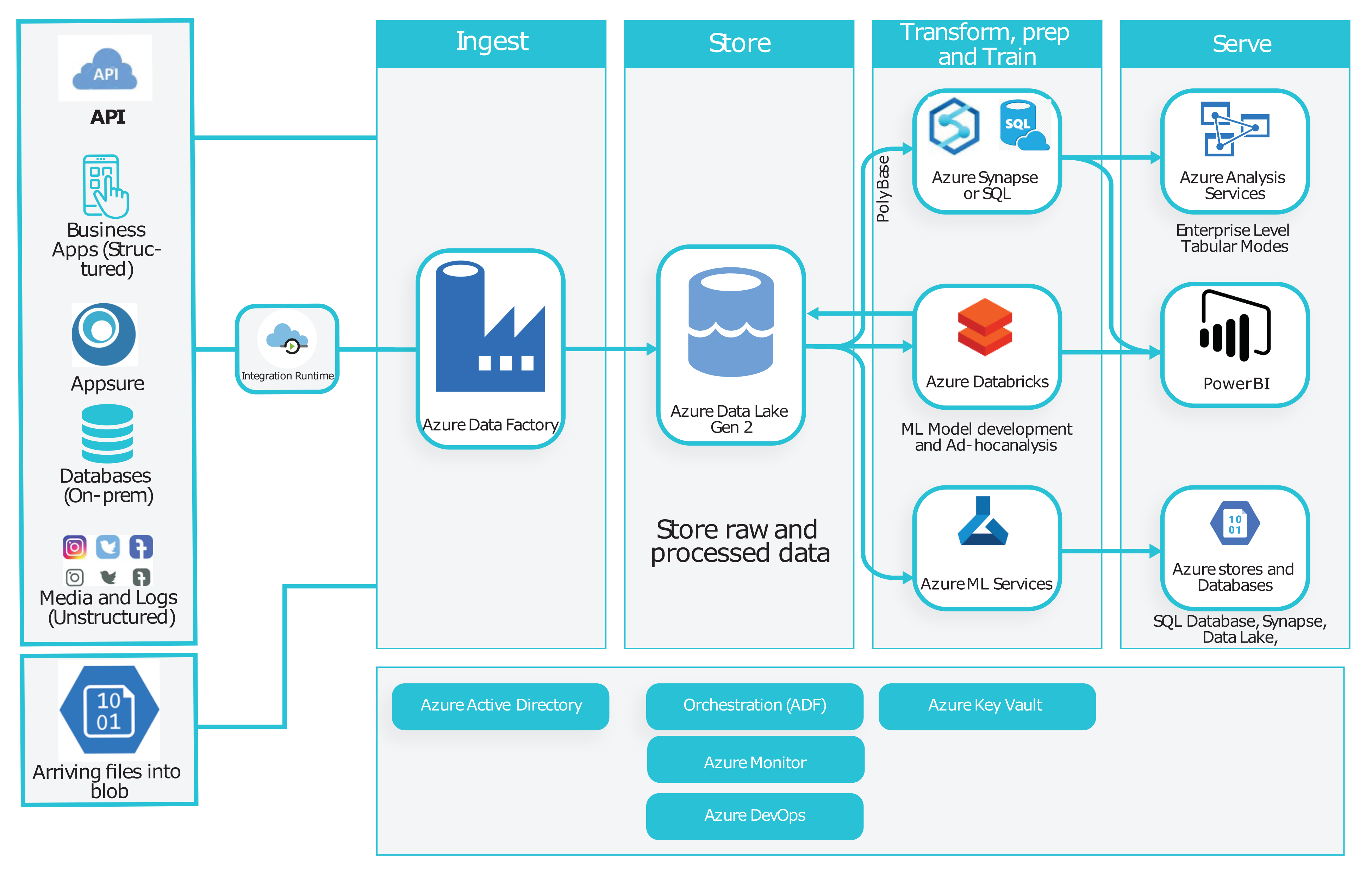
1. Ingestion Process
The ingestion process will load data from a variety of different data sources (structured or unstructured) and persist them in a central data lake storage (data store).
A common digestion pattern will be explained at the end of this document
2. Store
Ingested (raw) datasets (and business-ready datasets) will be stored in designated areas of Azure Data Lake. Datasets in the raw area (folders) will be useful for troubleshooting as well as meeting auditing and regulatory requirements.
On the other hand, permitted business users can access raw or processed datasets as the source of truth for specific analytics or reporting needs. As an example, data scientists can have a controlled access (through Azure Active Directory) to their related datasets and then feed them to azure ML services or Databricks machine learning library.
3. Processing (prep and train)
This architecture considers Azure Databricks service as the main processing engine.
Databricks easily links to data lake storage, process and augments different data types and prepare and land business-ready datasets in a specific area (folder) of data lake.
While Databricks is processing data, it can leverage a notification mechanism by connecting to azure logic apps and functions.
On the other hand, there is a need to supply updated historical datasets to the business via data serving layer. A layer is well suited for business intelligence and ad-hoc relational querying.
To satisfy this requirement, Databricks has another feature. It can organise data in relational-like databases on top of its file system.
Databricks can connect to Azure SQL Data warehouse by utilising JDBC connections and push its internal database entities through
This mechanism uses polybase under the hood which can get best of Azure SQL Data Warehouse massive parallel processing capabilities. This is a very fast process and can move gigabytes of data in a few minutes.
4. Data Service Layer
The architecture supports serving data both via data store (data lake) and the relational type store which can be Azure SQL Data Warehouse or Azure Analysis Services.
Datasets which have been processed and loaded into Azure SQL Data Warehouse will feed Azure Analysis Services (Tabular Models) in the final stage.
Azure Analysis Services is fully optimised to server Power BI and Excel services. It is the recommended portal for enterprise usage and provides a comprehensive level of security management and governing capabilities
It also separates business logics from reporting tools and centralises metrics definitions across the business.
5. Why Azure Databricks
Azure Databricks provides Apache Spark power and capabilities as a service in Azure platform.
It is an in-memory parallel processing system which can run X100 times faster than traditional map-reduce jobs.
Azure Databricks covers four main popular areas in one solution so it is an ideal tool set to deal with a variety of data processing and analytics requirements:
Spark SQL: provides access to data through popular SQL like commands
Spark Streaming: Support Real-time Live streams of data
GraphX: A comprehensive graph processing framework
ML Machine Learning Library: A distributed machine learning framework
Using Azure Databricks in this architecture brings a wide range of features and flexibilities to the table:
It is easy to setup and scale
oIt can digest and process large amount of data receiving through a variety of connection types such as ftp, email or RDBMS connections (one single engine).
Decoupling digestion and transformation logic from orchestration mechanism (ADF) in a very easy way. Queries and business logics are implemented in notebooks. ADF is only responsible for setting parameters and running notebooks.
Maintenance and extension made easy! Majority of logic will be written in SQL and Python (Java, R and Scala are also supported)
Implementing different data loading patterns (e.g. SCD) with an outstanding level of performance
It can link to data storage (Azure Data Lake) through AAD
All source codes (notebooks) will easily link to git repositories
It supports DevOps principals
It is easy to share workspaces and logics between different teams of developers
Databricks can use Azure security Key Vaults which eliminates hard-coding credentials in the source codes
6. Ingestion Pattern
It is very common for a data platform to receive data via secure ftp services or as attachments to standard emails.
Digesting these type of information needs a specific pattern to ensure incoming data is stored in the data store (azure data lake storage) and processed as soon as they have received.
Following diagram depicts a practiced pattern to implement digestion process for ftp and email data sources:
In this pattern, an Azure app listens to the blob storage and as soon as a new file is landed:
Another function retrieves metadata such as ADF pipeline name and destination path in Data Lake. Then it sends the information to logic apps
Logic apps moves the data from blob storage to data lake destination folder
Logic apps uses supplied parameters to trigger appropriate ADF (workflow)
Logic apps are also responsible to provide an adequate level of notifications
Then ADF pipeline will send file name and other meta data to run related Databricks notebook which will process raw data and makes it ready for business use
The mechanics of processing email attachments are very similar except for the fact that the data needs to be read from a standard attached file format.